Using simulation to study operating characteristics of stepped wedge cluster-randomised trials
Hi everyone,
We recently published an article in Statistics in Medicine on the use of joint longitudinal-survival modelling to accommodate informative dropout in longitudinal stepped wedge cluster-randomised trials. It’s the result of many moons of work, and I am extremely pleased that it is finally out - make sure to check it out!
While the paper focuses on the use of joint modelling to obtain unbiased treatment effect estimates, there is an interesting aspect of this work that (I think) is probably a bit underrated. Specifically, we developed an algorithm to simulate data from stepped wedge trials with different outcome types (continuous, binary, count) in the presence of dropout, either informative or not. This is implemented in the {simswjm} R package, which is openly available from the Red Door Analytics GitHub page.
Using this implementation of the simulation algorithm, we can use Monte Carlo simulation methods to study the operating characteristics of stepped wedge longitudinal trials in the presence of dropout. For instance, how much efficiency do we lose if some subjects do not complete the trial? What if the dropout rate is different between treated and non-treated participants? Well, we now have the possibility of studying this empirically using these new tools that we developed.
Say you have a stepped wedge trial with a continuous outcome, 4 intervention sequences, 5 periods, and 2 clusters randomised to each intervention sequence. Let’s assume a within-individual intra-class correlation coefficient (ICC) \(\rho_a = 0.588\) and a between-individuals ICC \(\rho_d = 0.021\) (same parameters from the simulation study in the paper). Moreover, let’s assume non-informative dropout at a constant rate, for simplicity but also to highlight some side effects of dropout that do not introduce bias in the analysis if unaccounted for.
We can now simulate 10,000 trials, where each cluster recruits between 15 and 150 participants, and study the inflation of standard errors in the presence of dropout. Specifically, we can analyse both the complete data (if no dropout occurred) and the actual observed data (where dropout happens) for each trial using the usual extension of the Hussey and Hughes model introduced by Baio et al. and compare the estimated standard errors of the estimated treatment effect.
If we plot the ratio of these standard errors for each simulated trial, we obtain the following plot:
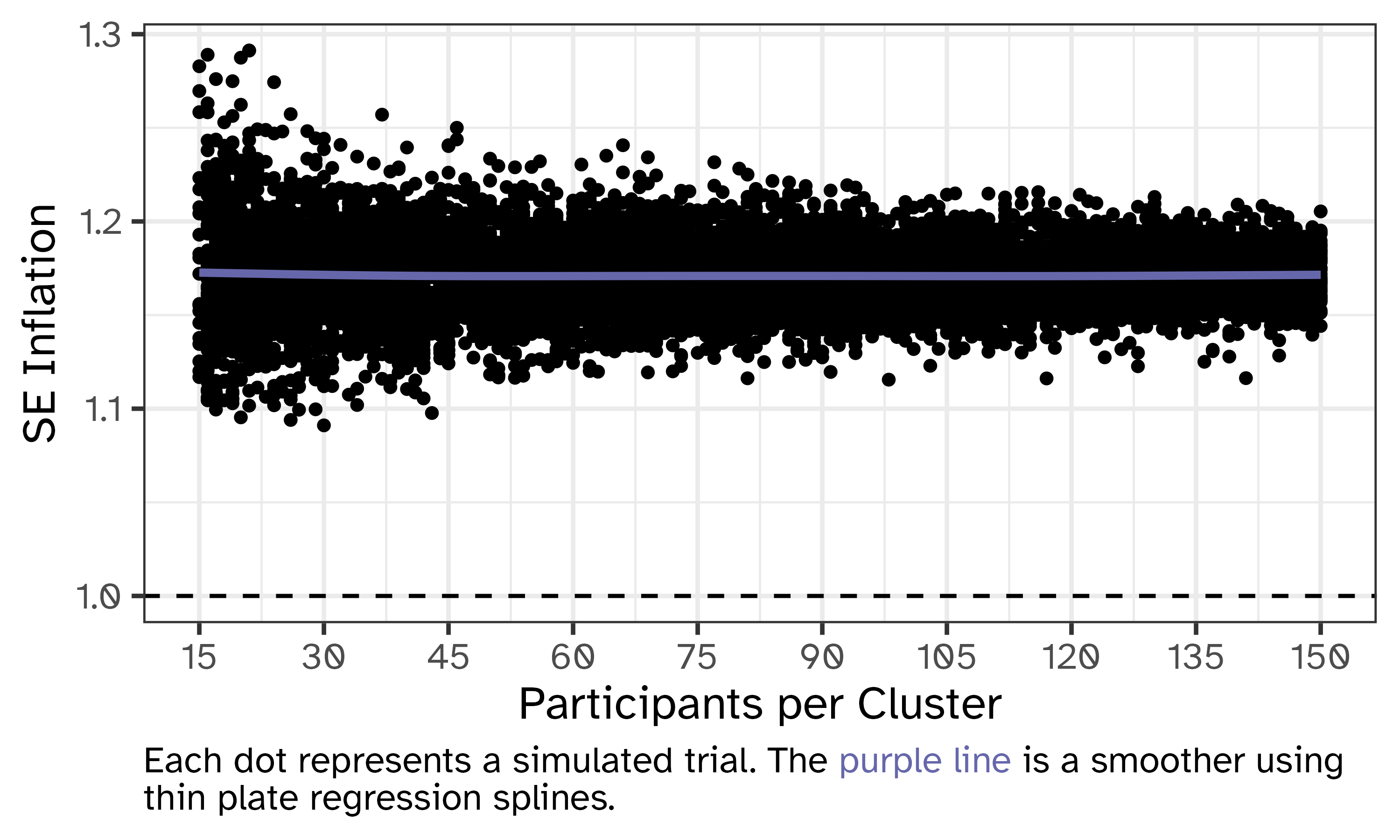
What we can see here is that, irrespective of how many subjects are recruited by each cluster, standard errors are 15/20% larger in the presence of dropout, on average. Given that dropout is not informative we are not getting biased estimates of the treatment effect (check out the results in the published paper for reference), but we lose efficiency thus affecting statistical inference. This provides a powerful tool that can be used at the design stage to ensure that study power is preserved if dropout was to happen.
Obviously, this is somewhat naive and for illustration purposes only - you can of course tweak all the data-generating parameters above and focus on different aspects or operating characteristics of a trial, but you get the idea. This is not rocket science, but I think it shows (once again!) how powerful of a tool statistical simulation can be. As someone much smarter than I am once said, if you can simulate it then you can understand it. Or something like that, I don’t know.
Anyway, remember to check out the paper and the R package, and just get in touch if you have any thoughts on this. You can also replicate the example above using the R script archived here and posted below: